|
|
|
A new approach to classification
of large diverse data sets
|
|
|
|
|
In our routine activities, we consciously and unconsciously sort out information on objects and phenomena of the surrounding world. We do it by referring them to specific groups by a variety of features such as novelty, importance, size, duration, edibility, taste, cost, and countless others. Obviously, without such systematization it would be impossible to not only develop concepts and knowledge, but to pursue any rational activity and even ensure the very existence of humans as living creatures (see Figure 1 below). It can be said that systematization of large diverse data sets by specific features is basic to thinking and human culture in general.

Fig.1. How animals classify surrounding objects
Modern information technologies (IT), both "paper" and electronic, intensively use various classification methods to store, search for, retrieve and compare data. In books, lists and catalogues contents are arranged by chapters, sections and paragraphs. Examples of software applications based on systemizing data are computer operating systems, internet search engines, electronic directories, application-specific databases, expert systems.
Electronic IT systems search for information specified by 1) combinations of keywords, 2) ranges of numeric parameters, 3) menu selections, and/or 4) consecutively narrowing queries which are usually implemented as opening respective sub-catalogues, sub-folders or web pages. Electronic systems allow systematization of extremely large data sets and they dramatically outperform any non-electronic system by speed, functionality and reliability. Moreover, computer knowledge representation technologies intended for classifying, organizing and otherwise processing large amounts of information are cornerstone of modern manufacturing, financial and social infrastructures.
|
|
|
|
|
 A short answer is that modern approaches allow us to efficiently systemize only data pertaining to a narrow subject. As an information architecture is extended to include descriptions of objects and phenomena with new and increasingly diverse properties, it often quickly becomes too expensive to develop, maintain and operate. Development of a computer system to deal with diverse data involves huge investments and usually requires significant restrictions of its functionality.
A short answer is that modern approaches allow us to efficiently systemize only data pertaining to a narrow subject. As an information architecture is extended to include descriptions of objects and phenomena with new and increasingly diverse properties, it often quickly becomes too expensive to develop, maintain and operate. Development of a computer system to deal with diverse data involves huge investments and usually requires significant restrictions of its functionality.
To clarify the origin of the problem, consider how we specify object groups (categories) of our interest when working with computer. Specification of an object group would typically mean selecting answers to one or more questions. Specific forms of answers depend on the user interface design: it could be entering a keyword or a numeric range, selecting a hyperlink or a menu item. For example, if you are looking to purchase a digital camera using the Yahoo portal, you may consecutively open sub-catalogues «Shopping» and «Electronics», then select «Digital Camera» from the menu «Select a Category». Then you should select name of the manufacturer, resolution in megapixels, media type and optical zoom, and enter a price range.
In response to your query the system displays a list of matching digital cameras and prompts you to select the next option «Memory» and enter an optional keyword. Thus, each selection option specifies one of the properties of a digital camera, while a set of options defines a combination of its properties.
What is required from such a system?
First, when making multi-criteria search the system should display only relevant (i.e. meaningful) search criteria while automatically defining what additional criteria make sense in combination with all previously specified properties. For example, criteria "Manufacturer" and "Price" are relevant for all manufactured goods, while "Megapixels" makes sense only for the category "Digital Camera". An intelligent search system, like Yahoo, should not display the last criterion when people browse washing machines and film cameras.
Second, the system should not allow contradictory and meaningless combinations of options by eliminating possibility of such errors. For example, when searching for digital cameras, any attempts to enter a negative price range, such as "$-500 to $0", should be ignored, as well as undoubtedly irrelevant key words, such as "petrol", "non-toxic", "religious" and the like.
Third, all relevant search criteria should be displayed simultaneously, so that the user may specify required properties in the order they like and ignore the options they prefer to leave open. For example, available image formats or minimum focusing range may be of primary importance for a particular user. Therefore, criteria "Image Format" and "Minimum Focusing Range" should be accessible immediately after entering the category "Digital Camera" together with all other applicable criteria.
At first, the requirements above may seem redundant. It is unlikely that someone will enter a negative price or knowingly input silly keywords when searching for a good. But when dealing with more complex information architectures it requires more user's attention and even special knowledge to make sure that the options are relevant and consistent. Without automatic verification both data input and search for data are subject to numerous errors. In addition, some knowledge representation systems have to support non-interactive generation of queries and therefore include an exhaustive set of rules to determine whether a query is relevant and consistent.
It might seem that in each particular case it is possible, in principle, to achieve proper operation via programming support. For example, both automatic switching of relevant criteria and analysis of options consistency can be programmed using a set of rules developed by area experts. But as the database gradually incorporates increasingly diverse data, the cost of analytical and programming work grows so rapidly that at a certain stage either further extension of information architecture must be suspended, or the system functionality restricted. So, the aforementioned theoretical possibility typically remains unattained.
Suffice it to note that the majority of knowledge representation systems fall short of the combination of the three requirements above. Those who regularly shop on internet know very few, if any, multi-criteria search engines that support detailed systematization of goods by their parameters. In course of a dialogue one can normally specify at most 5 to 8 «major» parameters while dozens more can be only obtained by going to a «Full Specifications» page for each specific model. An attentive buyer who wishes to carefully optimize her purchase has to spend from few hours to few days to collect and manually compare these remaining parameters.
Again, while this functionality restriction may be bearable when selling consumer goods, it is unacceptable in professional applications supporting health / engineering standards, taxes and customs, enterprise resource planning, military logistics, and other critical activities.
We emphasize that the three requirements above are only a minimum that is desirable from a knowledge representation system. In cases of more complex information processing the system should also comply with additional requirements discussed below in Section 3.
|
|
|
|
|
Interactive multi-criteria search for specific objects is only the simplest use case of an information system. But often it is the only one addressed by existing methodologies. At the same time, many fields of application require the support of complex comparison of data in addition to search. Let us discuss some examples.
- A physician must select one of 50 drugs of a specific kind which is not in the group counter-indicated for a given patient and compatible with 5 other (previously prescribed) medications.
- When planning for a merger of enterprises, it is necessary to identify what companies are shared and individual suppliers of these enterprises with respect to each of the 1000 given sub-groups of materials, equipment and other resources.
- An IT system analyst must identify which of available 100000 software components have the specified functionality and are compatible with the specified group of 100 other components by their interfaces.
Obviously, an interactive search for specific objects and manual comparison of their parameters would be very time-consuming in these cases. So, what additional features should an information system have to address the mentioned problems?
Fourth, a knowledge representation system should deal with not only individual objects but also categories of objects defined by combinations of properties, just like in interactive search. The system should be able to process complex combinations of properties which describe categories by 1) intersections of features, such as "ball bearing supplier of enterprise No.1 AND enterprise No.2", 2) their unions, such as "interface subsystems accepting input from "keyboard OR mouse", and 3) negations, such as "tranquilizers NOT counter-indicated for acute kidney conditions". Naturally, all these operations should be performed directly with category descriptions without searching through lists of individual objects.
Fifth, categories defined by consistent combinations of properties should be ordered by the «general-specific» relationship, just like chapters, sections and paragraphs in a book. However, unlike chapters, sections, etc., the categories should be allowed to have more than one direct general (also called parent) category, which makes it possible to classify objects by a number of different aspects simultaneously. Such an ordering known as polyhierarchical classification is necessary to consistently incorporate many generally accepted notions and concepts.
In particular, in computer science, the need of such structuring led to sometimes unsuccessful trials to implement the concept of multiple inheritance in object-oriented programming languages. It is equally important that a polyhierarchical classification directly supports an automatic check of object properties for their relevance and consistency (see requirements No.1 and No.2 in Section 2 above). For example, once all portable electric appliances are united into one common category, questions about type and parameters of used batteries make sense for all particular sub-categories of such appliances (players, notebook computers, electric shockers, hearing aid devices, wrist watches, etc.
Ordering categories in the form of polyhierarchical classification and support of complex category descriptions using AND, OR and NOT logical operations are mandatory for highly automated knowledge representation systems. These more demanding requirements considerably complicate already complex problems of analytical and programming support mentioned in Section 2, therefore additional degree of flexibility is required from the information architecture.
Sixth, the information architecture should ensure simplicity and ease of implementing unplanned changes in the data systematization scheme, so that sets of search criteria and selection options, i.e. sets of answers and questions, may be extended easily, without rapidly encumbering the system with more and more managing code and descriptive data.
To summarize the discussion from Sections 2 and 3, here is a short list of basic requirements to an "ideal" information system:
Six Keys to Power over Information:
- Automatic recognition of relevant search criteria (questions)
- Automatic control of consistency of selection options (answers)
- Simultaneous presentation of all relevant search criteria
- Processing complex category descriptions without retrieving individual objects
- Polyhierarchical ordering of categories by the "general-specific" relationship
- Ease of unplanned modifications and extensions
In many practical applications satisfying these six basic requirements is extremely problematic and cannot be done under existing knowledge representation technologies. Modern programming languages and formalisms simply lack concepts suitable for adequate description of sets of widely diverse phenomena and their efficient processing. Do not assume that this problem arises solely when processing extremely large data sets. In fact, it is extremely difficult to arrange objects starting from about 20 mutually dependent search criteria. In Sections 4 through 7 below we discuss the shortcomings of present-day data systematization techniques due to their lack of some of the six formulated qualities.
|
|
|
|
|
Let us first discuss the tabular data systematization scheme by taking Yahoo catalogue of household electronic appliances as an example (see above). In the simplest case all information on goods from the "Electronics" catalogue can be compiled into one large table where each column contains a description of one of the good's characteristics. Here is a simplified version of such table (Figure 2).
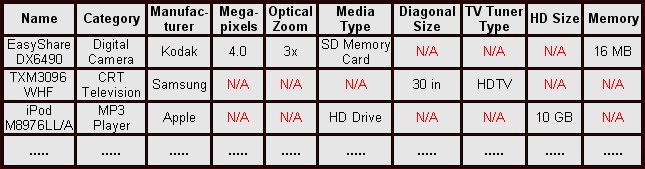
Fig.2. Table of household electronic appliances from Yahoo shopping catalogue.
A quick review of the table shows that 1) approximately 200 columns are needed for detailed description of goods from all 6 categories "Digital Cameras", "MP3 Players", "DVD Players", "Televisions", "DV Camcorders" and "Portable CD Players", as goods from each category are characterized by 20 to 40 properties, and 2) over 80% of table cells remain empty (N/A) since most properties make sense only for a few specific categories. In addition, the table shown in Figure 2 displays all parameters at once without consideration of their relevance and compatibility. Such table cannot be used for multi-criteria search directly because it would require manual selection of meaningful combinations from a huge list of parameters.
What would rational database developer do in this case? Of course, split the full catalogue into several categories and store descriptions of goods from each category in a separate table. Switching search criteria, checking selection options for consistency, etc, will be performed by a specialized managing program, just as it is implemented in Yahoo.
However, the database developer will soon discover that he has to break down the catalogue into increasingly smaller tables in order to display relevant criteria at proper stages of specialization. For example, for digital cameras using hard disks as storage media it makes sense to know the storage capacity of the disk, while television sets with built-in DVD player induces a whole range of questions on parameters of that player.
Therefore these sub-categories of goods should be represented by separate tables. In addition, many criteria related to parameters of power supply, storage format, memory capacity etc. are relevant for several categories at a time. To avoid multiplication of managing code and preserve consistency in case of changes, it would be reasonable to store these criteria in yet other tables, together with corresponding sets of valid options. As a result, the developer ends up with more and more different, subject-specific tables and more and more complex managing computer codes.
Tabular data systematizations are nothing but elementary components of a knowledge representation system. They serve to store small and uniform data fragments without providing any systematization themselves. With tabular data, the task of managing information architecture is the entire responsibility of a managing computer program.
|
|
|
|
|
Keywords are typically very poor at systemizing data. Due to multiple meaning of words in various contexts, differences in their interpretation, existence of synonyms, using keywords to describe object properties is often unreliable and inaccurate. Internet users know how long it may take to select a suitable combination of keywords for a search after excluding all thinkable variants of collateral, metaphorical, jargon and special meaning. In addition, keywords cannot be practically checked for consistency since they are not structured as a whole, i.e. they are not themselves systemized.
Therefore, free (i.e. arbitrarily selectable) keywords are useful for reference interactive search only. Their use should always be complemented by other, more effective data systematization techniques, or at least accompanied by visual analysis of the search results. They cannot be efficiently used in highly automated knowledge representation systems as a primary mean of building information architecture.
We should distinguish free keywords from controlled vocabularies that are implemented in many present-day applications. These applications prompt for selection of keywords from a strictly formalized vocabulary that precisely defines both the meaning of words and the context of their applicability. Such vocabularies allow the user to avoid ambiguous interpretations and effectively implement classification of keywords, something that greatly enhances their application potential. However, this does not resolve the problem of data systematization since it only boils down to the equivalent task of structuring a vocabulary.
|
|
|
|
|
Commonly known systems of nested catalogues (folders, directories) are the most obvious example of tree-structured information architectures. Figure 3 below shows an example of tree-structured system of nested folders in a Microsoft Windows Explorer window.
Fig.3. Directory tree in a Microsoft Windows Explorer window.
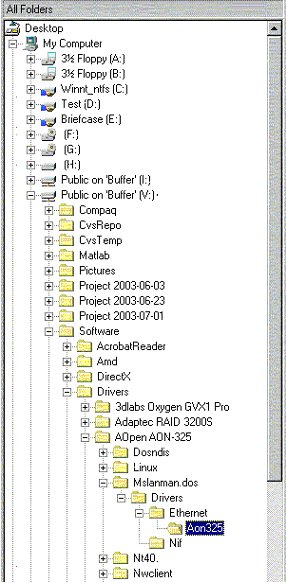
Tree-structured architectures consist of nodes connected by directed branches, representing some binary directed relationship so that each node has exactly one "parent" node, excepting the top-level node that have no parents. Depending on application, nodes may denote folders (directories) in a filesystem, document subsections, object categories, system states, etc., while branches denote entrances to nested subfolders (subsections) or valid transitions to more specific categories or states. Since rules of working with trees are completely independent from their applied meaning, any tree can be treated as a system of nested folders.
It should be emphasized that trees by their definition prohibit including a subfolder into more than one other folder simultaneously. This means that one can "get" required file (paragraph, object, state) only by opening all intermediate folders in a strictly prescribed order. For example, in Figure 3 it is impossible to include the subfolder "Aon325" simultaneously into "Ethernet" and "Nif". Therefore, its files become accessible only through a single chain "Desktop"
 "My Computer"
"Public on 'Buffer' (V:)"
"Software"
"Drivers"
"AOpen AON-325"
"Mslanman.dos"
"Drivers"
"Ethernet"
"Aon325" that determines path to the files.
"My Computer"
"Public on 'Buffer' (V:)"
"Software"
"Drivers"
"AOpen AON-325"
"Mslanman.dos"
"Drivers"
"Ethernet"
"Aon325" that determines path to the files.
Distributing files over nested folders is precisely tree-structured data systematization scheme. For example, information on goods from the «Electronics» section of Yahoo shopping catalogue could be organized into folder tree shown in Figure 4 in a Microsoft Windows Explorer window. The topmost folder «Electronics» is divided into 6 subfolders «Digital Cameras», «DV Camcorders», «DVD Players» etc.
In turn, each subfolder is subdivided into several other subfolders «Aiptec», «Bell&Howell», «Canon» etc. accordingly to names of manufacturers. Nested subfolders of the next three levels classify digital cameras by megapixels, optical zoom and storage media type. Innermost subfolders contain files with detailed specifications of the respective models.
Fig.4. Folder tree for arranging descriptions of household electronic devices.
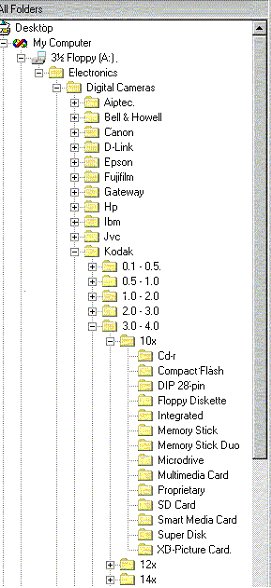
Thus, each level of nested subfolders corresponds to one of the item's parameters or properties, with same-level subfolders defining value options of that parameter. Therefore, opening a subfolder defines a selection option by one of search criteria provided by the information system.
The sequence of search criteria, and predetermined selection options depend on the hierarchy structure. For example, partitioning of "Digital Cameras" and "Televisions" should depend on specific features of these categories of goods. Therefore, tree-structured schemes allow hierarchical classifications with an automatic recognition of relevant search criteria and strictly consistent selection options. That is, they meet requirements No.1, No.2 and No.5. However, there are considerable shortcomings.
Trees fail to meet requirement No.3 (providing all relevant search criteria at once) since they impose a strictly predefined sequence of criteria and do not allow to by-pass any of them. It means that the database designer prescribes the sequence of displaying selection criteria to the user, i.e. ranks criteria by priority or importance. If the user is interested primarily in those parameters that were not considered most "important" at design time, the forced data arrangement can be quite inconvenient.
As an example, consider a case when the buyer uses tree-structured system of folders shown in Figure 4 to search for digital cameras with micro-disk as storage media. Since the partitioning by storage media type is made at the innermost level, in order to find all such cameras the user will have to go through all combinations of higher ranked parameters: name of manufacturer, megapixels and optical zoom. Such a buyer has to jump up and down over the folder tree for hundreds times.
Trees fail to meet requirement 4 (logical operations on categories). In trees, object parameters are combined by logical AND to denote simultaneous possession of several compatible properties ("Is a Digital Camera" AND "Manufactured by Kodak" AND "Has 4.0 Megapixels" AND "Has Optical Zoom 10X" AND "Uses SD Memory"). Categories (folders) cannot be defined by union or negation of properties (NOT "Manufactured by Kodak", "Has Optical Zoom 10X OR 12X") within the tree structure. This drastically limits classification functionality when comparing the data, as discussed in Section 3.
Finally, tree-structured information architectures fail to meet requirement No.6 (ease of modification) as they require to explicitly list all categories including intermediate ones that only serve to specify predefined selection sequences. This is what is commonly called "the predefined path problem". Whenever there are several simultaneously relevant search criteria, they multiply at intermediate levels so the number of intermediate categories grows exponentially reaching frightening magnitudes. Due to the corresponding increase in costs of analytical and programming work, trees are only convenient to build simplest classifications.
|
|
|
|
|
The widespread faceted classification methods are designed to overcome the predefined path problem pertaining to tree-structured information architectures. In faceted approaches, the entire classification is broken into several distinct aspects (facets), each described by a separate tree. In interactive multi-criteria search and other operations, object parameters can be specialized with simultaneously using all the facets in arbitrary order. Combinations of properties defined by different facets are treated as a system of relationships, for example, "manufactured at a specific location", "designed for a specific purpose", "has a specific engine", "written in a specific language" etc.
A faceted classification can be explained by the following example. Imagine that a computer filesystem has more than one tree of nested folders, with each file being «registered» simultaneously in all these trees, so that its location can be determined by several paths rather than one. These systems of nested folders are facets that describe ordering of files across independently meaningful «aspects» or «projections». For example, one of the facets may specify the purpose of goods, another one locations where they were manufactured, etc.
A systems user enters parameters of an object by selecting nested subfolders, just like in a tree. However, in this case he may enter parameters across various aspects in an arbitrary order using all facets simultaneously. While searching, the current object category is determined by a combination of properties across various aspects using logical AND.
Faceted knowledge representation schemes do not impose a strict sequence of specializations and do not require the database developer to list them all explicitly. That makes facets much more flexible and functional than trees. Nevertheless, facets are also fraught with serious shortcomings.
The main idea behind faceted classifications is to separate object properties into independent universal aspects so that each aspect is meaningful for all classified objects. However, in practice such separation is often problematic or even impossible. For example, questions about type and parameters of battery is meaningful for all portable electronic appliances from Section 3, while questions about optical parameters are relevant for all optical devices, whether electronic or mechanical, portable or stationary.
In order to correctly show domains of applicability of these parameters, relevant groups of search criteria should be represented as sub-trees within a facet. However, in this case the facet itself becomes very complicated, thus getting back to the «predefined path» and «categories multiplication» problems discussed in Section 6.
On the other hand, in order to avoid these problems it would be convenient to move groups of search criteria related to battery parameters, optical characteristics and many other locally relevant criteria to special facets. But those facets are not applicable to all categories of goods, so again a computer code has to be developed to make sure that they are used appropriately. As a result, the original system of independent universal aspects crumbles down, being transformed into a variety of locally applicable fragments managed by an application-specific program. In fact, the computer code will have to deal with the problem of data systematization rather than the original faceted information architecture itself.
Thus, in designing a faceted classification, the developer has to strike the right balance between the degree of complexity of individual facets and that of the managing codes, a problem that sometimes cannot be resolved satisfactorily. Attempts to formalize control of facets resulted in creation of a bulky mathematical apparatus that includes many auxiliary concepts such as hierarchical relationships, roles, purposes, sub- and meta-facets, etc.
In practice facets proved to be effective only for some of narrowly specialized data sets while in more complex cases the developers had to limit the system's functionality due to failure to meet requirement 6 (ease of modification). As a result, the majority of modern faceted knowledge representation systems do not control facet consistency (requirements No.1 and No.2, automation) thereby shifting the responsibility for data relevance and consistency onto their users.
In addition, facets, just like trees, fail to meet requirement No.4 (logical operations on categories). In standard faceted classifications, combinations of parameters defining categories are formed using only logical AND that limits possibilities of data organization and comparison. For example, when systemizing descriptions of goods, it would be useful to have a category including digital and analogue cameras, telescopes, microscopes and binoculars in order to define search criteria related to optical properties for all corresponding devices. However, once electronic goods are included into a special category within one of the facets, it is no longer possible to have a common category for all optical goods including electronic ones without developing extra descriptions and/or computer codes.
|
|
|
|
|
Our knowledge representation technique is not based on trees, but its main advantages can be explained by comparing it with trees and facets. Let us revisit the issue discussed in Section 6: how trees of nested folders (categories) are used for data systematization. First, categories serve as containers of objects: referring an object to a specific category means that the object has a set of properties encoded into a path to the respective folder. Second, they serve as menus (lists of options) for further specialization of properties.
When opening a folder, the user is offered a list of nested subfolders (which is equivalent to displaying the next search criterion) and, once one of them is opened (equivalent to selecting an option), the user passes to the next level of specialization. The intrinsic logic of dialog with the user is absolutely unrelated to the way how properties are specified: by mouse clicking on the folder icons
 in MS Windows Explorer window (see Figure 4) or, say, by selecting items from drop-down menus shown below in Figure 5.
in MS Windows Explorer window (see Figure 4) or, say, by selecting items from drop-down menus shown below in Figure 5.

Fig.5. Menus for specifying parameters of digital cameras.
Of the two mentioned category roles, the object container role is implemented in the same way in practically all classification systems. In order to distribute objects (files) over nested categories (folders), it is sufficient to record corresponding category numbers or names to object tables. The second role is more interesting: how exactly the menus are switched when object properties are specialized interactively. Of course, interactive work is only one of possible modes of use, and it is largely an issue of user interface. But we consider here the menu switching paradigm because it clearly shows what distinguishes one classification method from another. In fact, the background logic of menu switching determines the effective information architecture.
Tree-structured architectures provide only one menu at each stage of specialization. For example, navigating the tree of folders shown in Figure 4 is equivalent to the following sequence of menus and choices: 1) "Category of Electronics" (criterion)
"Digital Camera" (option), 2) "Manufacturer" (criterion)
"Kodak" (option), 3) "Megapixels" (criterion)
"3.0 - 4.0" (option), 4) "Optical Zoom" (criterion)
"10X" (option), etc. When properties are specified completely, that is, an innermost folder is reached, the menu hides away. Faceted information architectures provide several accessible menus simultaneously, each behaving as an independent tree with its own sequence of menu switching.
Our classification scheme provides for a much more flexible switching logic. Just like facets, when making multi-criteria search it offers several simultaneously accessible menus, each corresponding to a criterion relevant at current specialization stage. As properties are further specialized, the menus may be used in any order. But unlike facets, our classification scheme automatically recognizes what criteria are relevant at each specialization stage, i.e. for a given combination of properties. It is very important that the scheme intrinsically supports switching logic of unlimited complexity while with facets one has to resort to additional descriptions and constructions such as meta-facets.
For example, consider the sequence of menu switches shown in Figure 6 that let the user select an item to purchase .The sequence of specializations starts from a single menu asking about the item's broad category. Once «Electronics» is selected, new relevant search criteria «Purpose», «Portability», and «Processing method» appear. Any of these three menus may be used for further specification. Once the category (for example, «Optical») is selected, due to the choice just made two new criteria «Optics Family» and «Optical Zoom» become relevant.
They are shown together with two previous, still relevant and unused criteria «Portability» and «Processing method». These four menus may now be used in any order to further specify properties. Specialization may continue until relevant criteria are exhausted which means complete description of item properties.
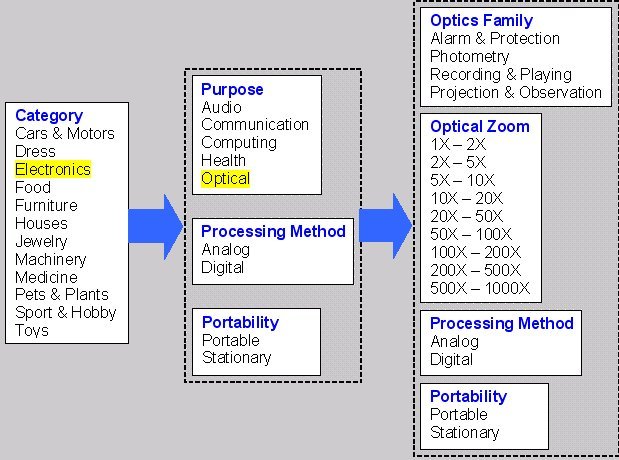
Fig.6 Simple example of the menu switching logic with our method.
The discussed method for specialization of properties should not be understood literally as a procedure of interactive selection described in this example. We do not propose a user interface. This example only shows the logic of controlling property relevance as cornerstone of our classification method. It should be emphasized that when our method is implemented in automated knowledge representation systems, properties do not have to be entered manually as in example of Figure 6. Instead, they can be automatically generated and processed by the system in complex combinations. This trivial example is given solely to explain the principal difference of our data classification scheme from trees and facets.
The idea of automatic recognition and simultaneous presentation of all relevant criteria is not new by itself. Many developers of classifications, knowledge representation systems, databases and other information-managing applications would attempt to implement this logic to maximum extent. However, all present-day approaches are based on programming support of switching logic, i.e. they fail to meet requirement No.6 (ease of extensions and modifications). In these approaches introducing new search criteria, new selection options, and changing conditions of their relevance and consistency invariably involve development of increasingly complex auxiliary descriptions and/or computer codes.
Imagine how inconvenient it would be to work with a computer if every time to create, copy, move or delete a subfolder you had to recompile some code, register new system components, restart computer etc. This is what the current state of data systematization technologies can be compared to.
The main advantage of our knowledge representation technique is that switching logic of unlimited complexity is implemented by using simple and uniform structures. Configuration of database and volume of managing computer code do not depend on the number of search criteria and selection options, or on the complexity of conditions determining their relevance and consistency.
Thus, our information architecture allows refining data systematization and extending the diversity of classified objects without additional expense for development of managing software or descriptions. That is why it dramatically simplifies development and maintenance of information-managing software and allows creation of more sophisticated intelligent knowledge representation systems than by using other approaches.
|
|
|
|
|
The basic idea of our approach can be explained via linguistic analogy. It should be noted that regardless of how data are systemized, categories of objects are always described as statements of object properties. These statements are formed by combining primary assertions such as "Is a Digital Camera", "Manufactured by Kodak", "Has 4.0 Megapixels", "Has Optical Zoom 10X", "Uses SD Memory". In interactive search primary assertions correspond to options selected in search criteria. An information architecture representing classification can be regarded as "grammar" determining the sequence and consistency rules for primary assertions.
In particular, trees form categories by combining primary assertions into ordered chains using logical AND (see Section 6). When specialization is refined by addition of a new assertion, what assertion options are available is strictly determined by the entire initial statement. Thus, the grammar of tree-structured arrangements consists of predefined lists of assertion options that can be added to each statement.
A set of mutually exclusive elementary assertions on any object property is called criterion of classification. For multi-criteria interactive search, a criterion is simply a question plus a set of predefined answer options, like the menus shown in Figure 5 above. Classification criteria can be conveniently depicted as forks looking likewise branched nodes of a tree. This is how the menus from Figure 5 are graphically represented:

Fig.7. Graphical representation of the criteria matching menus in Fig.5.
Forks in Figure 7 originate from blocks representing the categories for which corresponding criterion is relevant. In particular, in tree-structured information architectures each non-leaf (i.e. not innermost) category represents domain of applicability of exactly one criterion.
Our methodology employs a much more general grammar of statements of object properties. In particular, compared to trees:
- a category may introduce several rather than one new relevant criterion, i.e. a statement describing that category may be further specialized by an assertion from any of several simultaneously applicable new criteria;
- a category may have several parents, i.e. the statement describing a category may be obtained by several sequences of specializations ("paths") rather than one;
- category describing statements may be formed from primary assertions using not only logical AND, like in trees and facets, but also by complex combinations of AND, OR, NOT, i.e. intersections, unions and negations.
At first it may not seem obvious that such a general grammar can be efficiently implemented in a general case without resorting to sophisticated auxiliary programs or auxiliary data structures. Even trees that seem so simple, in practice require manual input of a big list of categories. Facets, while only partially addressing problems of trees, have drawbacks related to introducing complex meta-descriptions that require development of sophisticated managing software. What is it in our methodology that enables it to be implemented efficiently?
The answer is very simple:
 The system of classification criteria (answers, menus) is chosen in such a way that the domain of applicability of each criterion is either
The system of classification criteria (answers, menus) is chosen in such a way that the domain of applicability of each criterion is either
- the entire set of classified objects (the "universe"), or
- a category described by combination of primary assertions from more general criteria of the same classification system (combination of answers to more general questions, selections from upper-level menus).
If this condition is met, the criteria automatically form a polyhierarchy that we call generating polyhierarchy of criteria. In mathematical terms, polyhierarchy is represented by a directed acyclic graph (DAG), or a partially ordered set. In terms of object-oriented methodology, it can be viewed as class hierarchy with multiple inheritance. This is how this polyhierarchy is formed: its first, or "topmost", level consists of criteria applicable to all the classified objects. The second level includes criteria whose domains of applicability are categories defined by the first level criteria; the next level - those with domains of applicability defined by criteria of any previous levels, and so on.
The generating polyhierarchy, although being very concise, mathematically rigorously determines all permissible sequences of specializations and consistency rules of primary assertions, i.e. it defines the grammar of data classification, i.e. the information architecture. The word "generating" here denotes its remarkable property and purpose:
The generating hierarchy implicitly describes the full set of classification categories as the set of all valid statements allowed in this grammar. Therefore, it becomes unnecessary to explicitly list categories unlike in trees and facets (within individual facets). This makes the whole classification structure very simple and concise. When designing a database for a particular application, the designer has to define only the grammar of data systematization while avoiding a host of secondary problems: exactly what categories are required, how to rank by importance unrelated criteria, how to implement relationships and meta-descriptions, and more.
It is easy to see that the categories defined by a generating polyhierarchy of criteria form their own polyhierarchy by the "general-specific" relationship.
Note 1. The generating polyhierarchy is a template or "skeleton" that exhaustively determines the information architecture and implicitly describes the full resulting system of categories. It is a compact, observable, portable and self-sufficient data structure. It can be re-used as 1) a template for further systematization of one or several similar data sets, 2) a component of a more general classification and 3) a prototype for structuring a more detailed data system. For this reason designing a generating polyhierarchy can be fully separated from the stage of associating it with a specific data set.
Our approach can be interpreted as construction of a grammar for valid statements on object properties with built-in automatic deduction of individual statements.
In contrast, tree-structured information architectures would require explicit enumeration of all valid statements, and faceted ones would require enumeration of all clauses, i.e. parts of statements, corresponding to categories within facets.
Figure 8 shows a fragment of the generating polyhierarchy from the example in Figure 6.
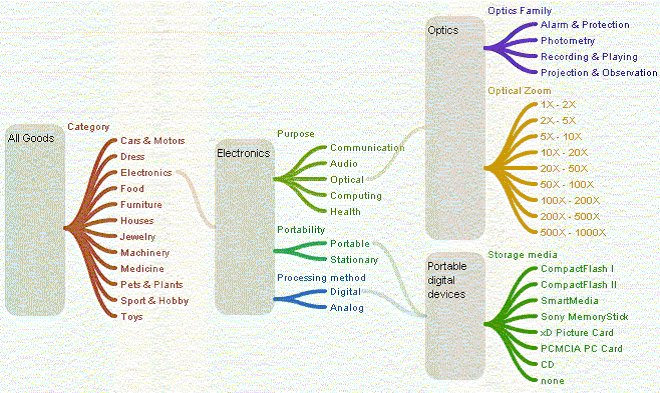
Fig.8. A fragment of generating polyhierarchy corresponding to the example from Fig.6.
Figure 9 below shows a more complex example: of a generating polyhierarchy for classification of transportation vehicles. This example is given to demonstrate the advantages of our approach to building information architectures compared to trees and facets in those non-trivial cases when dividing properties into completely independent aspects is problematic and the use of multiple inheritance of categories is a solution. Note that generally speaking, multiple inheritance in the system of categories can be achieved without multiple inheritance in generating polyhierarchy. In this example, however, both of them take place.
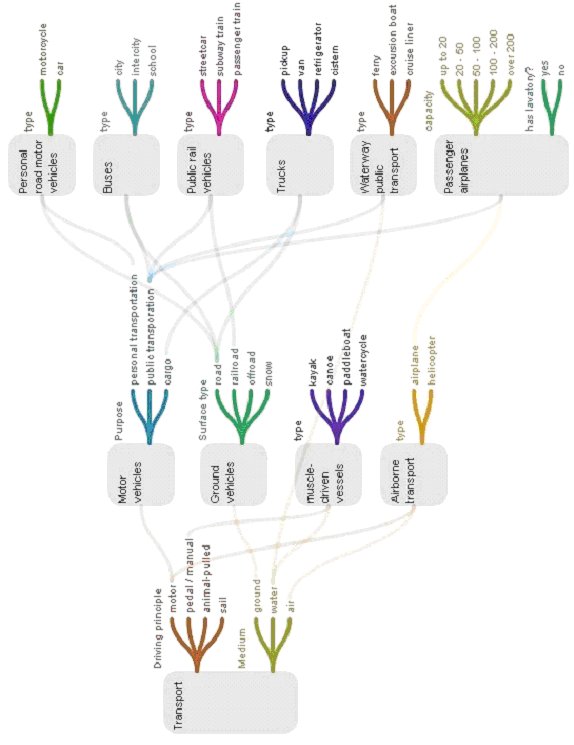
Fig.9. A fragment of generating hierarchy for classification of transport vehicles.
Apart from its main characteristic feature noted at the end of Section 8 (simple and uniform concepts and structures), this approach has several other merits:
- it is compliant with the six basic requirements specified in Section 3 thereby supporting the widest range of applications;
- it introduces a formalism for effective operation on compound descriptions in terms of generating polyhierarchies that can be used as formal language for development of next-generation knowledge representation systems, and it is already known how that language can be further extended and generalized;
- it requires storage of only a tiny fraction of categories, while forming all other necessary categories dynamically in run time;
- it considerably reduces the required computer resources by enabling efficient implementation of few standard operations;
- it may be implemented on standard database platforms without developing application-specific software, with possible exception of the routines supporting user interfaces;
- special knowledge is not required for understanding and implementation of the method, since it is based on a very simple system of basic notions.
|
|
|
|
In practical implementation of our approach, a number of auxiliary concepts and data structures are used. They are briefly described in the table below.
| Name |
Brief description |
| criterion |
A set of mutually exclusive options of primary assertions on an individual object property. For example criterion "Color" consisting of options {"red", "yellow", "white"}, and criterion "Shape" {"square", "circle", "hexagon"}. |
| branch of criterion |
An option making part of the criterion, such as "yellow" is branch of the criterion "Color". |
| attribute by criterion |
A primary assertion as part of attributive expressions (see below). For example, "yellow" is a primary assertion that can be used in an expression like "yellow circle". |
| category |
An imaginable set of potentially existing objects whose properties can be described by attributive expressions. In our trivial example, "yellow circle", "yellow square", "white hexagon" are some of the categories. The database permanently stores only descriptions of non-empty and root categories. Descriptions of all other categories to be used for search, browsing and complex data comparison are generated dynamically when querying the database. |
| attributive expression |
Code of a compound statement describing a category as combination of attributes. See also Note 2 below. |
| root category of a criterion |
The category representing domain of applicability of a given criterion in accordance with the requirement
from Section 9. Several criteria may originate from the same root category. |
| generating polyhierarchy |
The whole set of classification criteria possessing property
 from Section 9 that defines the information architecture as grammar of statements encoded by attributive expressions. Specifications of root categories participate in the definition of generating polyhierarchy.
from Section 9 that defines the information architecture as grammar of statements encoded by attributive expressions. Specifications of root categories participate in the definition of generating polyhierarchy. |
| induced polyhierarchy |
An (imaginable) system of categories that can be described by various attributive expressions within the grammar determined by the generating polyhierarchy. The induced hierarchy is not stored, but is automatically retrieved when working with classification. |
| |
Note 2. The specific form of attributive expressions can be chosen depending on what logical operations need to be used in the given application (see requirement No. 4 from Section 3). For example, if categories are always defined by combining primary assertions using solely logical AND, the simplest form of attribute expressions called simple collection will be sufficient to systematize the data. Alternatively, if categories have to be defined using logical OR and NOT, then more complex forms called collections with branch unions and unions of simple collections should be used. However, the mentioned three forms are only few of all thinkable ways to combine primary assertions into compound statements.
The task of systemizing data is performed in two stages. First, a generating polyhierarchy should be constructed, i.e. a set of criteria should be chosen and partially ordered. At this stage it is absolutely unnecessary to list all possible branches of criteria, still less all classification categories. It is enough to list only branches defining domains of criteria applicability, and to describe the respective root categories of the criteria in terms of attributive expressions.
At the second stage an available set of objects should be associated with the generating polyhierarchy. This procedure is quite similar to distributing files over nested folders: At this stage permanent attributive expressions defining non-empty categories are automatically recorded. All other categories that may be needed for performing various tasks with the classification are not stored but rather dynamically retrieved while working with the database.
The classification can be further refined and extended by modifying the generating polyhierarchy. Expanding a set of categories required in order to add objects with new values of existing properties (such as adding a new color) reduces to trivial addition of new branches to existing criteria. More complex modifications required, for example, to 1) increase the depth of specialization or 2) merge several classifications into one, can be performed by including into the generating polyhierarchy new criteria while automatically extending or merging the stored permanent attributive expressions.
When searching for, retrieving and comparing data, all logical operations are performed directly with attributive expressions without referring to the list of available objects. Knowledge of objects is not required for logical operations with the classification.
Thus, implementation of our method allows to support full functionality of classification, i.e. browsing the induced polyhierarchy of categories, verification of applicability and consistency of properties, menu switching logic, complex comparisons etc., even if the list of available objects is empty. That makes the classification usable at a very early stage of database design and development.
|
|
|
|
|
The main benefit from applying our information technology comes in form of a dramatic cut of costs of development, maintenance and operation of automated knowledge representation systems by reducing labor for their analytical and programming support. Unlike any other data systematization approach, it allows to systemize data of widely diverse content and efficiently manipulate data while meeting the six basic requirements from Sections 2 and 3. Finally, it is based on a very simple system of basic concepts that does not require any special knowledge to understand, implement and use it. Thus, our method offers a powerful formal tool for construction and applied use of information architectures that are too complex to be built using any other existing approach.
The proposed methodology is designed to reduce the cost of development, maintenance and operation of any applications intensively using (poly)hierarchical data systematization, such as:
- Taxonomical, expert, logistic, and content management systems;
- Enterprise resource planning and project management systems;
- Artificial intelligence, machine learning and data mining systems;
- Intelligent control systems and robots;
- Application-specific data and knowledge bases;
- Internet search engines;
- Online documentation and help subsystems;
- Electronic lists, catalogues and directories;
- Compilers for subject- and aspect-oriented programming languages;
- Instrumental tools for generative and intentional programming;
- Components of computer operating systems, such as folders, registry, organizers, etc.;
- Component-based software engineering systems (CBSE).
The following analogy is appropriate here. Before centuries X-XIII European scientists used exclusively Roman numbers, which were quite suitable for dating historical events but absolutely inconvenient for arithmetic calculations. Since performing operations with Roman numbers required knowledge of a system of complicated rules, only a small group of "initiated" intellectuals was in command of arithmetic. There was a saying "Learn to add and subtract anywhere, go to a university to learn multiplication, but only in Paris they teach you how to divide". With introduction of Arabic (more exactly, Indian) numbers, arithmetic operations became so simple that calculations, even very complicated at the time, could be practiced by a vast majority of "ordinary mortals" while the cumbersome system of rules that existed before simply became redundant.
All modern methods of data classification can be traced back to the tree-structured classification scheme explicitly formulated in the early XIX century. The most successful of modern approaches is the faceted classification proposed for the first time by S.R. Ranganathan, a librarian from India, in 1938. Facets proved very convenient for arrangement of library catalogues and other simple cases of data systematization. But further application of this methodology for ordering of more complex data required a host of auxiliary constructions and rules. By its resulting complication and lack of elegance, it bears a striking resemblance to the ancient arithmetic in Roman numbers.
Our approach introduces a new formalism for building information architectures which is not based on the "tree" principles. This formalism 1) allows to describe complex polyhierarchical architectures in a much simpler and more observable way than other methods, 2) allows to efficiently perform a wide range of operations wanted from a knowledge representation system without resorting to auxiliary content and rules, and 3) greatly outperforms facets by its versatility. In this sense, its introduction can be justly compared to the transition from Roman to Arabic numbers.
|
|
|
| Pavel Babikov. January 10, 2004 |
|
|
|
What's new:
QNT classification scheme is presented at the IASTED International Conference 2004 in Innsbruck.
Now QNT classification scheme is described in the comprehensive popular form,
click here.
Current versions:
ExLAF77 1.02
|
|